LLVM
LLVM 是 Low Level Virtual Machine (低级虚拟机)的首字母缩写, LLVM 发展至今已不再是“低级”虚拟机了,而是一个编译器的基础设施系统框架,提供程序分析、代码优化、机器代码生成等功能。
LLVM 工具链
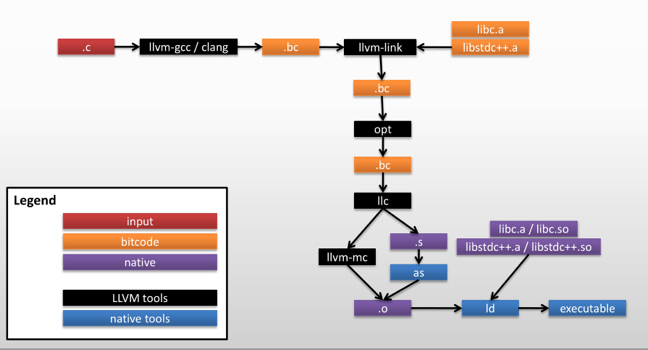
LLVM 有专门的文件格式 .ll(可读的 LLVM 字节码文件,即 LLVM IR 文件)、 .bc( LLVM 字节码文件),同时 LLVM 也有其他的配套工具链用于编译、优化、链接等。.bc 文件比 .ll 文件多进行了汇编阶段,因此我们可以通过反汇编 .bc 文件得到 .ll 文件。下面我们以 main.cpp 和 fib.cpp 为例介绍 LLVM 工具链。
1 | // fib.cpp |
1 | // main.cpp |
llvm-as
将 .ll 文件汇编为 bc 文件:
1 | llvm-as main.ll -o main.bc |
llvm-dis
将 .bc 文件反汇编为 .ll 文件:
1 | llvm-dis main.bc -o main.ll |
llvm-link
传统的编译器一般是对 obj 文件进行链接,LLVM 也可以对 .ll 和 .bc 文件(以下统称 LLVM 字节码文件)进行链接。
llvm-link 接受 .ll 和 .bc 文件,进行链接并可输出 .ll 和 .bc 文件:
1 | llvm-link main.ll fib.ll -S -o linked.ll |
lli
LLVM 可以直接运行 .ll 和 .bc 文件。
lli 执行 .ll 和 .bc 文件:
1 | lli linked.ll |
注:lli 工具使用 JIT (即时编译)作为执行 LLVM 字节码文件的默认方法,若你的源码中包含对库函数或其他外部函数的调用,lli 运行时一般会出错。因为正常编译时,链接器会处理这些调用的外部函数,而 LLVM 字节码文件尚未经过链接,这些外部函数在 LLVM 字节码文件中只是一些符号,直接通过 lli 运行会出现未定义错误。
llc
LLVM 可以将 .ll 和 .bc 文件编译为通用汇编语言。
llc 编译 LLVM 源文件到用于指定的体系结构的汇编语言:
1 | llc main.ll -o main.s |
opt
LLVM 还可以对 .ll 和 .bc 进行优化,LLVM 的优化能力也是 LLVM 的一项突出能力。
注:
当使用
-O0编译(默认即是-O0)时,Clang向每个函数添加optnone属性,这阻止了以后的进一步优化,为了防止这种情况,可以添加-Xclang -disable-O0-optnone选项。1
clang++ fib.cpp -Xclang -disable-O0-optnone -emit-llvm -S -o fib.ll
- 当希望进行调试时,最好使用
-O0或-O1编译,因为优化可能会改变控制流,导致指令执行顺序发生变化;还可能直接将一些潜在的bug优化掉(尽管bug没有了,但这是编译器优化解决的,不代表代码正确,你甚至不知道bug的存在,当你更换编译选项或者编译器时,bug就又出现了)。 - 越高的优化级别生成的代码一般执行速度更快,但代码大小也普遍更大。
clang是一个驱动程序,给clang传入优化选项实质是传给了opt。
opt 可以对 .ll 和 .bc 文件进行优化,opt 可以接受的优化选项很多,这里不再赘述。opt 还可以生成控制流图(Control Flow Graphic ):
1 | > clang++ fib.cpp -emit-llvm -fno-discard-value-names -S -o fib.ll |
你会得到一些 .dot 文件,你需要配置 Graphviz ,执行 dot ._Z3fibi.dot -Tpng -o fib.png 。

opt 还支持以下的可视化图形帮助理解分析逻辑:
1 | --view-callgraph - View call graph |
opt 可以根据硬件平台的不同执行不同的优化,可以参看编译器优化做指令调度时是怎么考虑不同的微架构下对同一个指令的执行周期数是不同的? - RednaxelaFX的回答 - 知乎以及使用clang: how to list supported target architectures?查看 LLVM 支持的平台和 CPU 。
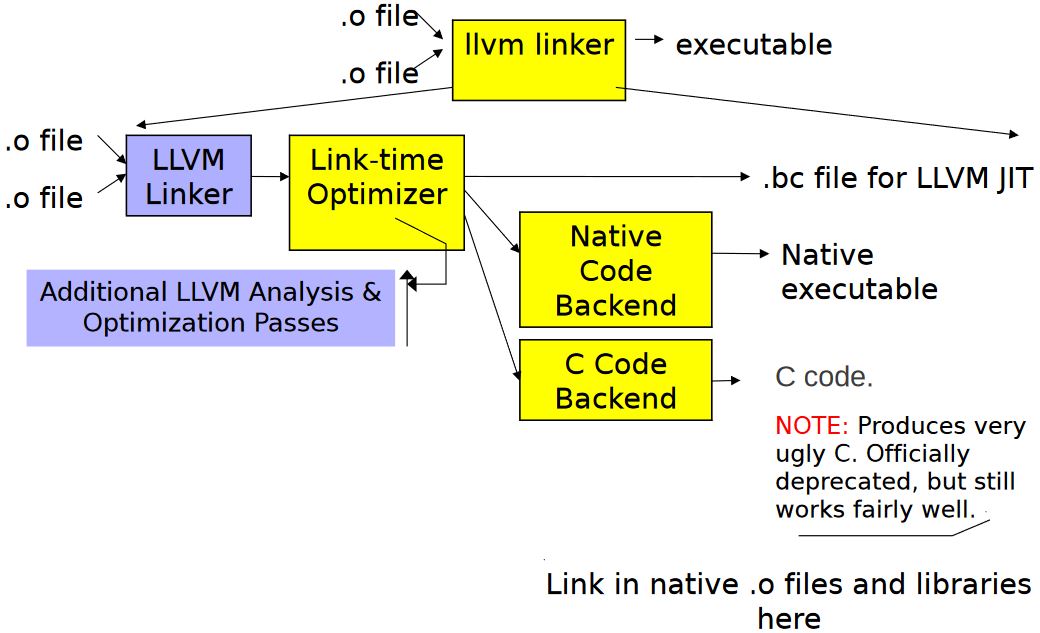
lld
LLVM 拥有配套的链接器 LLD,可以进行链接时优化(Link Time Optimization ),而且相对于 GNU ld ,链接速度更快,编译输出更小,具体请查看 LLD 官网。
可以在编译时添加 -fuse-ld=lld 选项来指定 LLD 链接器:
1 | clang++ main.cpp -fuse-ld=lld -o main.exe |
LLVM 通过 LLVM IR 来实现 LTO,如果想使用 LTO ,需要在编译每个待链接的文件以及链接这些文件时都添加 -flto 选项:
1 | clang++ main.cpp -flto -O1 -c -o main.o |
关于 LTO ,可以查看官网上 LLVM LTO 的介绍,以及 GCC LTO的介绍。
注意:
Clang和GCC都支持LTO,但由于LTO是通过中间表示(GCC上为GIMPLE,Clang上为LLVM IR)实现的,所以不能Clang和GCC的LTO不通用。- 若要使用
LTO,建议使用相同的选项编译参与链接的所有文件,且必须在编译和链接时添加选项-flto。但优化标志-Og、-O2和-Os可以作为优化属性传递,而不会受限于编译时和链接时间标志应该相同的情况。 - 在链接时传递的优化和目标选项将被忽略。
- 有时需要在编译
.obj文件时添加-O1等优化选项,才会启用LTO。
lldb
LLVM 也有对应的调试器 LLDB,LLDB 与 GDB 功能类似,但命令更加友好,而且 LLDB 具有与 Clang 相同的优点,也就是它可以高亮显示调试和错误信息。可以登录 LLDB 官网,学习 LLDB 的教程,以及查看 LLDB 与 GDB 命令的对照,你也可以首先学习 GDB 的教程 RMS's gdb Debugger Tutorial。
LLVM IR 文件的布局
Target Information
1 | ; ModuleID = 'main.cpp' |
target datalayout 为 target 的数据布局,target triple 为 target 的平台信息。
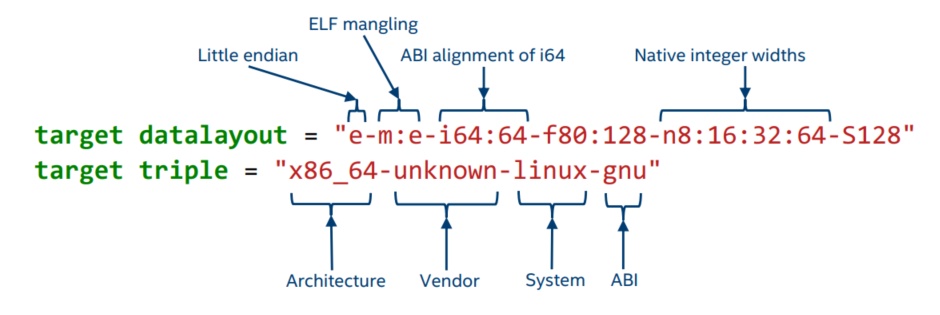
1 | i64:64 // 指定支持的整型的对齐单位,这里即是指支持64bit的整型,且以64bit对齐(存储整型的起始地址必须是128的倍数) |
1 | f80:128 // 指定支持的浮点类型的对齐单位,这里即是指支持80bit的浮点类型,但是以128bit对齐(存储浮点数的起始地址必须是128的倍数) |
1 | n8:16:32:64 // 指定一组支持的以位为单位的整数类型 |
其他具体信息,参看datalayout。
我的 target triple 为 "x86_64-w64-windows-gnu",即 Windows x64 操作系统上以 MinGW 为运行时环境(一般 Windows 系统上以 MSVC 为运行时环境, Windows 系统和 GCC 搭配来使用 LLVM 较为麻烦,但我觉得 MSVC 实在是太臃肿了。不过电脑配置如果满足要求,还是建议在 Windows 系统上使用 MSVC,因为许多软件在 Windows 系统上支持甚至唯一支持 MSVC 。使用 MSVC不仅省去了不少麻烦,而且 Windows 开发人员早晚跳不过 Visual Studio 。)。
可以通过 clang -v 查看 Clang 的版本和 target 信息,例如我的 Clang具体信息为
1 | clang version 9.0.0 (tags/RELEASE_900/final) |
Clang 编译时可以通过 --target 选项指定编译的目标平台,从而实现交叉编译,当然你需要有对应的运行时库(也就是说,假如你在 Linux 平台上下载了 MSVC 的运行时库,你就可以在 Linux 平台上编译 MSVC 支持的程序)。还可以将不同语言编译到 LLVM IR 层面进行链接,实现多语言的相互调用。这是 LLVM 非常大的一个优势,借助于 LLVM IR,LLVM 实现了平台独立性和灵活性。
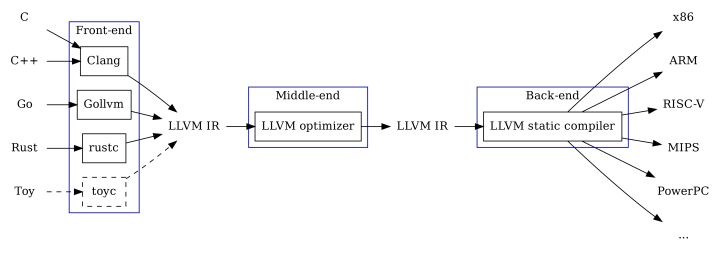
Clang 支持下列 target triple的组合,具体可以查看 Clang 的文档:
1 | The triple has the general format <arch><sub>-<vendor>-<sys>-<abi>, where: |
常用的 target triple 有:
1 | arm-none-eabi |
LLVM IR 文件的架构
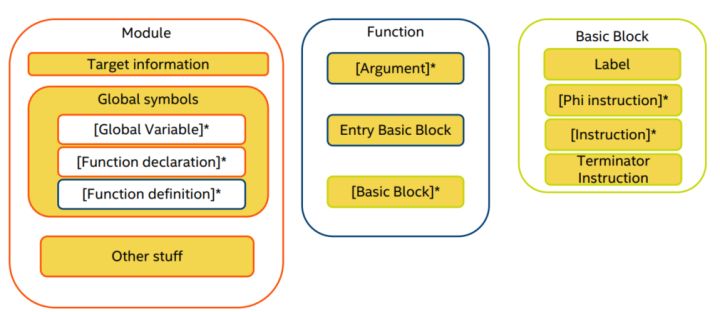
LLVM IR 文件从高到低由 Moudle 、Function 、 Basic Block 和 Instruction四个层次组成。
SSA (静态单分配)
定义
SSA形式是指程序中的每个变量必须且只能在定义时初始化。
1 | int x = 10; |
编译器为了进行代码优化,会对变量的定义和使用进行分析,主要有两种:
使用-定义链(
Use-Definition (UD) Chains):对于给定的变量
x的定义,它的所有使用是什么?定义-使用链(
Definition-Use (UD) Chains):对于给定的变量
x的使用,它的所有可达性定义是什么?
不幸的是,UD 和 DU 检查的花费可能会非常昂贵。

这是由于 x 可以重复赋值(也即重定义)导致的,自然地,我们可以想到让每个变量只能定义一次(可以类比 Java 中的 static final 常量,但略有不同,Java 中的 static final 常量可以延迟赋值,把赋值语句放在 static 块中)。

但 SSA 在处理控制流分支时存在一个问题:

变量每次赋值在 SSA 中都成为了一个新的变量,在线性运行时没有问题,但在遇到分支时就无法判断要使用那个新变量了。我们需要$\Phi$ 节点来实现控制流。
$\Phi$ 函数
$\Phi$ 函数将各个控制流分支路径上的定义合并为一个单一的定义

传统指令集并不支持 $\Phi$ 函数(即 LLVM IR 中的 phi 指令)的概念,LLVM 会对 phi 指令进行 Phi destruction ,将 phi 指令变为底层支持的汇编命令,例如我们可以通过在各个控制流分支路径上插入语句定义一个共享变量来实现 $\Phi$ 节点,也可以将因赋值而新定义的变量分配到同一个寄存器,从而实现在 LLVM IR 层次上保持 SSA 形式,而在寄存器层次上实质为同一变量。可以阅读llvm的reg2mem pass做了哪些事情? - 蓝色的回答 - 知乎。

初级 SSA
- 每个赋值都会生成一个新的变量。
- 在每个插入点为所有分支中的新变量插入 $\Phi$ 节点。
最小化 SSA
- 每个赋值都会生成一个新的变量。
- 在每个插入点为处于活跃期的分支中的新变量插入 $\Phi$ 节点。活跃期定义是从变量第一次被定义(赋值)开始,到它下一次被赋值前的最后一次被使用为止。
什么时候插入 $\Phi$ 函数
对于变量 x ,我们当且仅当以下情况时在 Z 中插入 $\Phi$ 函数:
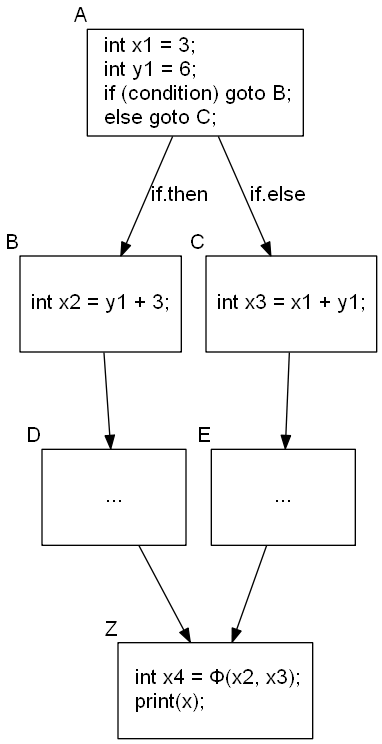
- 变量
x在各个分支(if.then、if.else)总共定义了多于一次。 - 变量
x新定义所在的块都可以到达块Z,且块Z是变量x新定义所在块的最先公共后继。
可以应用 Lengauer-Tarjan 算法计算支配树和支配边界判断插入 $\Phi$ 函数的块,关于支配树和支配边界还可以阅读构造Dominator Tree以及Dominator Frontier。
SSA 在编译优化中的作用
常量传播(
constant propagation)当 v $\leftarrow$ c 或 v $\leftarrow$ $\Phi$ (c, c, c) 时将
v替换为c,并将 v $\leftarrow$ c 和 v $\leftarrow$ $\Phi$ (c, c, c) 语句删除。复写传播(
copy propagation)当 x $\leftarrow$ y 或 x $\leftarrow$ $\Phi$ (y, y, y) 时将
x替换为y,并将 x $\leftarrow$ y 和 x $\leftarrow$ $\Phi$ (y, y, y) 语句删除。常量折叠(
constant folding)当 v $\leftarrow$ expression(c1, c2, …) 时可以将右值表达式计算出结果以替换右值表达式。
无用代码消除(
dead code elimination)- 假设所有变量都是常量,直到该变量值改变。
- 假设所有基本块都无法执行,直到该块被执行。
通过可达性分析,将常量进行折叠,并消除无用代码。
SSA 参看书目
LLVM IR 基本语法
简要介绍 LLVM IR 的基本语法常用的指令,详细文档请参看LLVM Language Reference Manual。
基本语法
1 | ; Function Attrs: noinline nounwind optnone uwtable |
注释
; 表示单行注释的开始。
标识符
LLVM IR 中的标识符分为两种类型:全局的和局部的。全局的标识符包括函数名和全局变量,会加一个 @ 前缀,局部的标识符会加一个 % 前缀。一般地,可用标识符对应的正则表达式为:
1 | [%@][-a-zA-Z$._][-a-zA-Z$._0-9]* |
函数
1 | define dso_local i64 @_Z3fibi(i32 %n) #0 |
定义了一个函数,其中 i64 代表 64 位整数,即 C/C++ 中的 int;@_Z3fibi 是函数名且代表函数是全局的;括号内是参数列表。#0 是指向函数属性的标记符。
数据类型
数组
语法
1 | [<elementnumber> x <elementtype>] |
数据元素在内存中是连续存储的。对于索引超出静态类型所指定的数组末端没有限制(尽管在某些情况下对于索引超出已分配对象的边界有限制)。这意味着一维”可变大小数组“寻址可以在零长度数组类型的 LLVM 中实现。例如,LLVM 中 pascal 风格数组的实现可以使用 {i32, [0 x float]} 类型。
结构体
语法
1 | %T1 = type { <type list> } ; Identified normal struct type |
结构类型用于表示内存中的数据成员集合。结构的元素可以是任何具有大小的类型。
通过使用 getelementptr 指令获得指向字段的指针,可以使用 load 和 store 访问内存中的结构。使用 extractvalue 和 insertvalue 指令访问寄存器中的结构。
结构可以选择“打包”结构,这表示结构的对齐方式是一个字节,并且元素之间没有填充。在非打包结构中,字段类型之间的填充是由模块中的 DataLayout 字符串定义的,这是匹配底层代码生成器所期望的内容所必需的。
常用指令
alloca
语法
1 | <result> = alloca [inalloca] <type> [, <ty> <NumElements>] [, align <alignment>] [, addrspace(<num>)] ; yields type addrspace(num)*:result |
返回一个指针。分配的内存是未初始化的,从未初始化的内存中加载会产生一个未定义的值。如果分配的堆栈空间不足,则操作本身未定义。
alloca 指令也可以用来分配结构体。
load
语法
load 的语法较为复杂,具有多种形式,但常用的形式一般如下:
1 | %0 = load i32, i32* %n.addr, align 4 // 从地址%n.addr中读取i32型数据 |
store
语法
store 的语法较为复杂,具有多种形式,但常用的形式一般如下:
1 | store i32 %n, i32* %n.addr, align 4 // 向地址%n.addr中读取i32型数据%n |
call
语法
1 | <result> = [tail | musttail | notail ] call [fast-math flags] [cconv] [ret attrs] [addrspace(<num>)] |
1 | %call2 = call i64 @_Z3fibi(i32 %1) // 调用fib函数,返回值赋给%call2 |
ret
语法
1 | ret <type> <value> ; Return a value from a non-void function |
1 | ret i64 %10 // 返回%10 |
br
语法
1 | br i1 <cond>, label <iftrue>, label <iffalse> |
在执行条件 br 指令时,将对 i1 参数求值。如果该值为真,则控制流到 iftrue 标签参数。如果 cond 为假,则控制流到 iffalse 标签参数。br 指令的无条件形式以单个 label 值为目标。
phi
语法
1 | <result> = phi [fast-math-flags] <ty> [ <val0>, <label0>], ... |
phi 指令在逻辑上接受在当前块之前执行的前任基本块对应所指定的值。
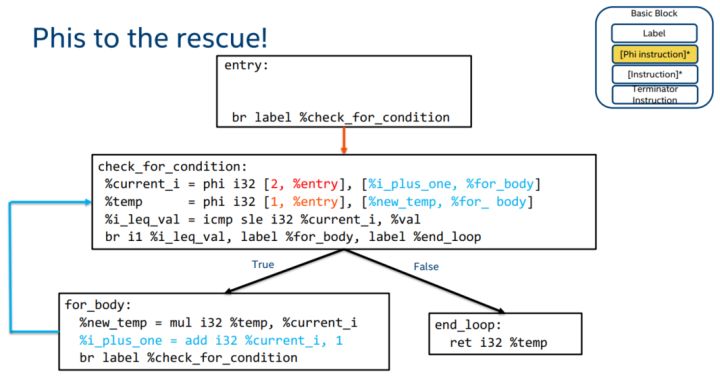
phi 指令主要用来解决 SSA (静态单赋值)带来的问题。不过 SSA 带来的变量不能重复赋值问题也能通过指针来解决,可以向一个不变的地址上多次执行 store 指令从而实现多次赋值。
要想在 LLVM IR 中使用 phi 指令,可以应用 -mem2reg 优化:
1 | clang++ fib.cpp -Xclang -disable-O0-optnone -emit-llvm -S -o fib.ll |
注意仍然要添加 -Xclang -disable-O0-optnone 编译。
同理要想在 LLVM IR 中屏蔽 phi 指令,可以应用 -reg2mem 优化(默认情况下即使不使用 phi 指令):
1 | clang++ fib.cpp -Xclang -disable-O0-optnone -emit-llvm -S -o fib.ll |
getelementptr (GEP)
语法
1 | <result> = getelementptr <ty>, <ty>* <ptrval>{, [inrange] <ty> <idx>}* |
第一个 ty是第一个索引使用的基本类型,第二个 ty 表示其后的基址 ptrval的类型。<ty> <idx> 是第一组索引的类型和值,<ty> <idx>可以出现多次,其后出现的就是第二组、第三组等等索引的类型和值。要注意索引的类型和索引使用的基本类型是不一样的,索引的类型一般为 i32或 i64,而索引使用的基本类型确定的是增加索引值时指针的偏移量。
理解第一个索引
- 第一个索引不会改变返回的指针的类型,也就是说
ptrval前面的*对应什么类型,返回就是什么类型 - 第一个索引的偏移量的是由第一个索引的值和第一个
ty指定的基本类型共同确定的。

上图中第一个索引所使用的基本类型是 [6 x i8],值是1,所以返回的值相对基址 @a_gv 前进了 6 个字节。由于只有一个索引,所以返回的指针也是 [6 x i8]* 类型。
理解后面的索引
- 后面的索引是在
Aggregate Types内进行索引。 - 每增加一个索引,就会使得该索引使用的基本类型和返回的指针的类型去掉一层。

我们看 %elem_ptr = getelementptr [6 x i8], [6 x i8]* @a_gv, i32 0, i32 0 这一句,第一个索引值是 0,使用的基本类型 [6 x i8] , 因此其使返回的指针先前进 0 x 6 个字节,也就是不前进,第二个索引的值是 1,使用的基本类型就是 i8( [6 x i8]去掉左边的 6 ),因此其使返回的指针前进一个字节,返回的指针类型为 i8*( [6 x i8]*去掉左边的 6 )。
GEP如何作用于结构体

只有一个索引情况下, GEP 作用于结构体与作用于数组的规则相同,%new_ptr = getelementptr %MyStruct*, %MyStruct* @a_gv, i32 1使得 %new_ptr 相对 @a_gv 偏移一个结构体 %MyStruct 的大小。

在有两个索引的情况下,第二个索引对返回指针的影响跟结构体的成员类型有关。譬如说在上图中,第二个索引值是 1,那么返回的指针就会偏移到第二个成员,也就是偏移 1 个字节,由于第二个成员是 i32 类型,因此返回的指针是 i32* 。

如果结构体的本身也有 Aggregate Type 的成员,就会出现超过两个索引的情况。第三个索引将会进入这个 Aggregate Type 成员进行索引。譬如说上图中的第二个索引是 2 ,指针先指向第三个成员,第三个成员是个数组。再看第三个索引是 0 ,因此指针就指向该成员的第一个元素,指针类型也变成了 i32* 。
注: 本 GEP 小节引用了知乎用户@ZRN-BF的文章A Tour to LLVM IR(下)。
Clang 介绍
上文已经提到 Clang只是前端的一个 Driver ,从编译器架构上来说,Clang 只是用来进行词法分析、语法分析、语义分析、中间代码生成的编译器前端。 Clang 需要借助其他编译器后端来实现机器代码生成。这也是 Clang 的 Target Information 的作用。 Windows 上 Clang 可以与 MSVC 或 MinGW 搭配起来构成一个完整的编译器。
Clang 生成中间代码(也就是 LLVM 字节码),并在此基础上进行一系列优化操作,再进一步生成可执行文件。由于 Clang 需要和其他的编译器后端组合,所以在编程源码时就会出现许多由于前后端不搭配导致的问题。
Clang 交叉编译
前后端的 target 不同,可以在编译时添加 --target 选项来指定后端 target ,具体参看Target Information。
Clang 异常处理模型
首先介绍一下 MinGW-w64 的异常模型的异同,可以参看GCC Wiki 和 Stackoverflow:
SJLJ(setjmp/longjmp): 支持32位和64位系统。传统的异常处理模型,性能较差,即使没有抛出异常,也会导致较小的性能损失(严重异常代码的性能损失约为15%),但有时这种损失可能更大。SEH(Structured Exception Handling): 只支持64位系统。性能更加优异,当从不使用SEH的库中抛出异常时,SEH异常将导致非常严重的错误。DWARF:只支持32位系统。需要使用DWARF-2(或DWARF-3)调试信息。DW2 EH会导致可执行文件稍微膨胀,因为大型的调用堆栈展开表必须包含在可执行文件中。
一般情况下,x86_64 可选为 seh 和 sjlj,i686 为 dwarf 和 sjlj 。你可以通过这个回答中的方法查看 Clang 和 GCC 的当前的异常处理模型,也可以阅读 Exceptions Handling in LLVM。
普通 Windows 用户在使用 Clang 时可能更倾向于使用官网预编译的二进制版本直接安装,官网的编译版本通常是:
1 | Target: x86_64-pc-windows-msvc |
预编译 Clang 默认的异常处理模型为 seh 。如果你使用 MSVC 作为后端,那么可能没有问题,因为 MSVC 同样使用 seh 。但如果你使用 MinGW 作为后端,就需要查看 MinGW 的异常处理模型是否与 Clang 默认的异常处理模型相同,如果不同, 可以添加 -fdwarf-exceptions 、 -fsjlj-exceptions 和 -fseh-exceptions 来指定异常处理模型,或者添加 -fno-exceptions 禁用异常机制(一般不建议)。
Clang 编译流程
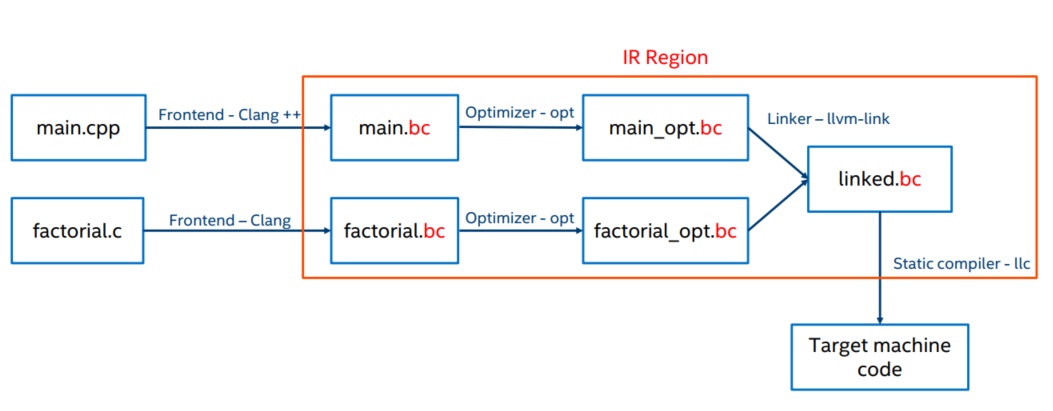
Clang或Clang++(以下以clang++为例说明,如有两者不同的特殊情况会专门指出)对待编译的源文件main.cpp进行预处理,例如将#include的文件复制到源文件中、展开宏定义、插入内联函数以及处理#if、#endif、#ifndef等命令。使用-E选项指定编译器只进行预处理。
1 | clang++ main.cpp -E -o main.i |
Clang++将main.i编译为汇编代码文件。使用-S选项指定编译器只进行预处理和编译。若添加上-emit-llvm选项,则会生成LLVM IR(一种LLVM专用的中间表示,类似于汇编的可读的字节码)文件,否则会生成一般汇编代码文件。注:
Clang的Release和Debug版生成的.ll文件略有不同,Release版默认生成的.ll文件会丢弃变量的名字,你可以添加-fno-discard-value-names选项指定Clang保留原有的标签和标识符以增加可读性。1
2clang++ main.cpp -S -o main.s
clang++ main.cpp -S -emit-llvm -o main.llClang++将汇编代码文件进行汇编生成LLVM bitcode(专指.bc文件)文件。使用-c选项指定编译器只进行预处理、编译和汇编。若添加上-emit-llvm选项,则会生成LLVM bitcode文件,否则会生成.obj文件。1
2clang++ main.cpp -c -o main.o
clang++ main.cpp -c -emit-llvm -o main.bc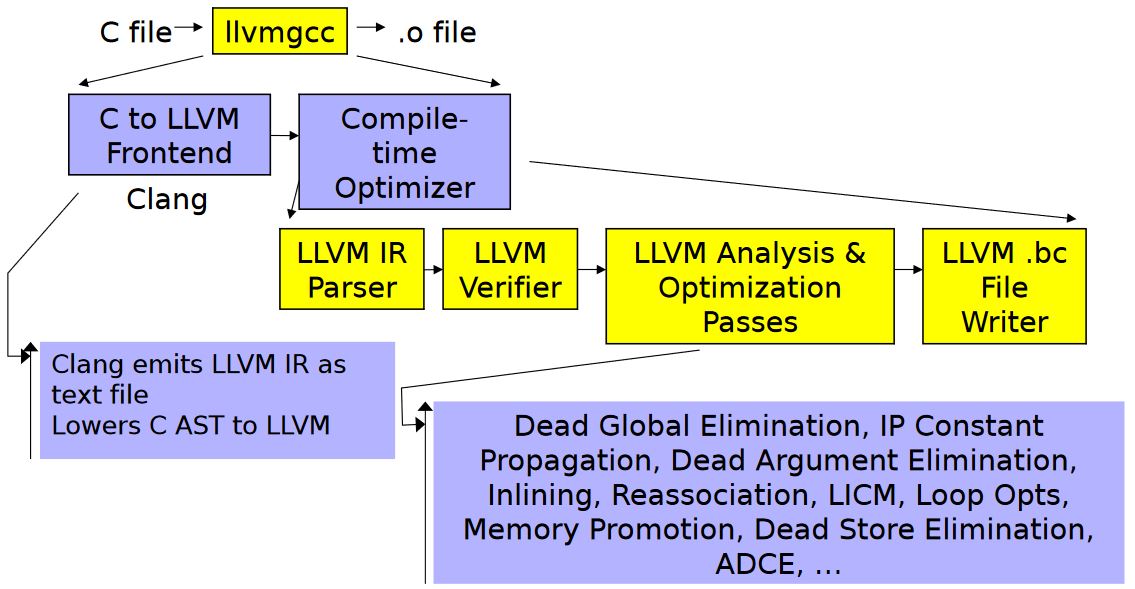
Clang++将多个.obj文件或LLVM bitcode文件链接起来,形成一个完整的文件。使用-r选项指定编译器只进行符号链接,把多个.obj文件链接为一个总的.obj文件。1
clang++ main.o factorial.o -r -o linked.o
注:
libstdc++、libc++和msvcrt都是C++标准库的一个实现。libstdc++是Linux上GCC的默认运行时库;libc++是Mac OS上Clang的配套运行时库;msvcrt是Windows上VS的默认运行时库。C++会进行Name Mangling,Name Mangling是将函数名和变量名编码为惟一的名称,以便链接器能够将语言中的名称区分开,以便实现重载。Name Mangling按照一定规则根据函数名和函数参数列表生成混淆后的函数名。使用以下命令可以得到混淆前的函数签名:
1
c++filt -n <mangled-name>
Clang++将.obj文件编译生成可执行文件。1
clang++ linked.o -o main.exe
注意:
clang和clang++只是前端的一个Driver(驱动程序),clang和clang++对源文件的处理本质上都是通过调用LLVM工具链实现的。Clang的命令行用法参看文档。clang和clang++在预处理、编译和汇编阶段是完全相同,clang++本质上是clang的一个软连接,它通过后缀名来判断是C还是C++,-x <language>会指定文件语言类型 。不同的是clang++既可以链接C++标准库也可以链接C标准库,clang只能链接C标准库。1
2
3
4clang++ test.c -o test.exe // correct
clang test.cpp -o test.exe // error
clang test.cpp -c -o test.o // correct, because clang works same as clang++ during preprocess, compile and assemble steps
clang test.cpp -stdc++ -o test.exe // correct, clang complie successfully after specifing link library
Clang 编译选项
Clang 兼容 gcc 的所有编译选项,同时 Clang 有附带许多功能,我们可以通过添加编译选项来使用。
-m32 和 -m64
使用 32 位的 clang 或 gcc 时默认生成 32 位的程序;使用 64 位的 clang 或 gcc 时默认生成 64 位的程序。
当 Windows 下使用 64 位的 gcc 编译 32 位的程序时,必须将对应的动态链接库地址加入到 PATH 环境变量( Linux 下可以设置 LD_LIBRARY_PATH )中,或者在编译时选择静态链接。
注: clang 对 32 位和 64 位交叉编译配置较为麻烦,远不如直接使用 MinGW-w64 。配置交叉编译的选项最好使用专门的构建工具(如 CMake , Makefile ),直接配置环境变量不仅费时费力,而且环境变量是全局的,对编译其他程序极不友好,很容易造成冲突。
-ftime-trace
Clang 9.0.0 增加了 -ftime-trace , 这能够以友好的格式生成时间跟踪分析数据,对于开发人员更好地理解编译器将大部分时间花在何处以及其他需要改进的领域非常有用。
1 | > clang++ test.cpp -ftime-trace -c -o test.o |
在speedscope中你可以看到以下的交互可视化图形:
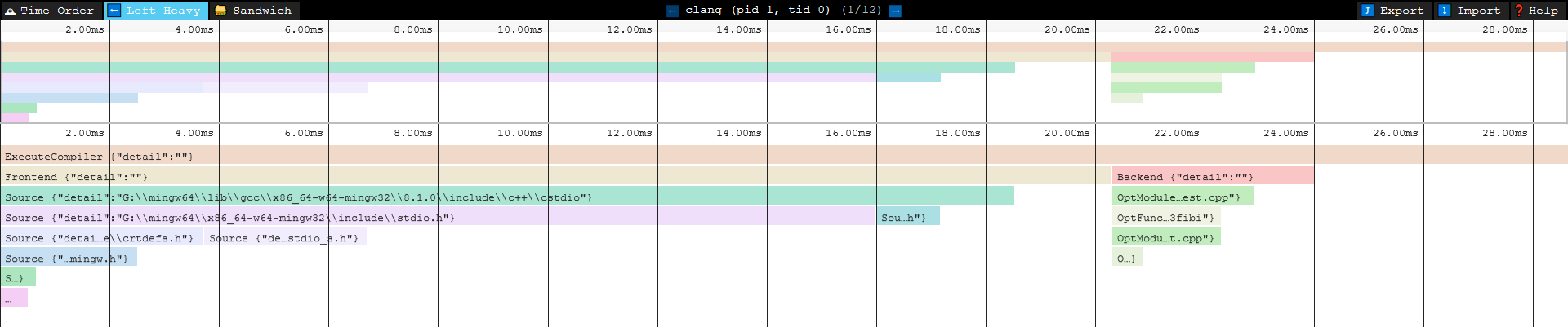
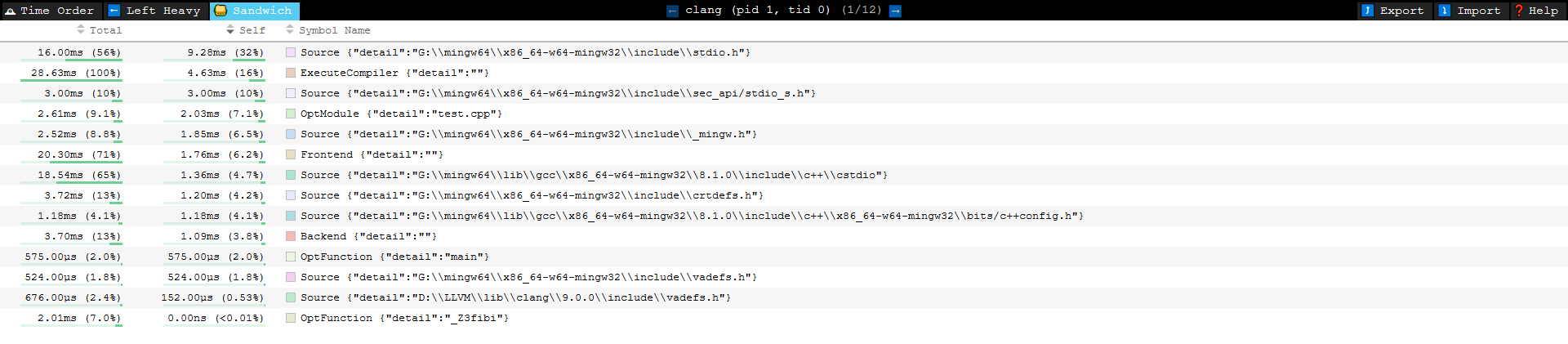
Clang Build Analyzer工具有助于聚合来自多个编译的时间跟踪报告,并输出关于“什么花了最多的时间”的信息摘要。
--analyze
1 | clang --analyze -Xclang -analyzer-checker="cplusplus" test.cpp |
--analyze 选项启动 Clang 的静态代码分析,能够检查代码中存在的错误与缺陷。 Clang 可以检查进行特定的检查( checker ),Clang 内置的 checker 查看available_checks。
Clang 拓展
clang-format
clang-format 是一个代码格式化工具,clang-format 内建了 LLVM,Google,Chromium, Mozilla, WebKit 五种格式,可以通过 --style= 指定,也可以使用 --style=file 从 .clang-format 文件中加载自定义代码格式配置( clang-format 的配置文件名必须是 .clang-format )。
1 | clang-format --style=LLVM -i main.cpp |
-i 选项指定就地更改 main.cpp。
clang-tidy
clang-tidy 是一个基于 clang 的 C++ linter工具。它的目的是提供一个可扩展的框架,用于诊断和修复典型的编程错误,如样式违规、接口误用或可以通过静态分析推断出的 bug 。clang-tidy 是模块化的,提供了一个方便的接口来编写新的插件。clang-tidy 提供了许多 check,可以在 -check= 中指定一个或多个 check (用 , 隔开)其他详细用法查看官网。
1 | clang-tidy -checks=-*,clang-analyzer-*,-clang-analyzer-cplusplus* test.cpp -- |
注:
Windows下使用要在命令行最后添加--。Windows下clang-tidy的-check和-config选项组合在一起可能会出现问题,可以把所有选项都放在-config中。
clang-check
clang-check 与 clang-tidy 功能类似,在没有显示指定任何选项的情况下运行 clang-check 将运行 -fsyntax-only 模式(检查语法是否正确)。只有在指定 -analyze 时,才会执行静态分析工具,但不能同时指定 -fsyntax-only 和 -analyze,-check 选项可以参考官网。
clang-check 还可以输出代码的 AST ,具体用法执行 clang-check -help 。
LLVM 优化
clang 一般只有在开启优化时才会内联函数,如果使用 -fno-inline 选项或 -O0 优化级别(默认优化级别),GCC 将不内联任何函数,可以使用 -Winline 选项来确定函数是否没有内联以及为什么没有内联。此时可以使用 __attribute__ 机制。
在函数声明末尾 ; 之前添加 __attribute__((always_inline)) ,可以强制编译器内联函数(尽可能内联,必须满足内联函数要求)。
C++ 中内联编译限制:
- 不能存在任何形式的循环语句。
- 不能存在过多的条件判断语句。
- 函数体不能过于庞大。
- 不能对函数进行取址操作。
- 内联函数声明必须在调用语句之前。
Clang 使用中遇到的问题
MinGW-w64与float.h不兼容:1
2G:\mingw64\x86_64-w64-mingw32\include\float.h:28:15: fatal error: 'float.h' file not found
#include_next <float.h>member [...] in archive is not an object一般有2个原因:- 链接的对象或库文件位数不一致,例如
x64和x86混合。 - 使用
LTO时没有在编译和链接时都添加上flto。
- 链接的对象或库文件位数不一致,例如
- 链接静态库时出现
error: undefined reference to 'xxx',一般是由于缺少库文件或者链接顺序错误。被链接的库应该放在最后面。
_参考资料_
[1] RednaxelaFX Blog